
Note: This post continues from Part 2, which covered the Kaggle Learn
Pandas,Intro to SQL,Advanced SQL,Data CleaningandFeature Engineeringmodules. Earlier posts in the series include Part 1 (Intro to Deep Learning,Computer Vision,Data Visualization,Intro to AI Ethics,Machine Learning Explainability) and “30 Days of ML” (Python,Intro to Machine Learning,Intermediate Machine Learning).
I finally reached the last leg of my learning journey with Kaggle Learn.
The end was in sight, and once I complete the Geospatial Analysis, Natural Language Processing, Intro to Game AI and Reinforcement Learning and Time Series modules, I would have finished all the available courses.
Geospatial Analysis
Among the 17 modules, I found this to be one of the most interesting and informative courses. Being able to project real-world data onto physical locations, and then use it to create insightful visualisations and run meaningful analysis is a very useful skill to have.
Using the GeoPandas and Folium packages, the well-structured lessons started with the basics of generating simple maps and understanding coordinate reference systems. They then progress to working with interactive maps, geocoding and spatial manipulation and end with versatile proximity analysis techniques.

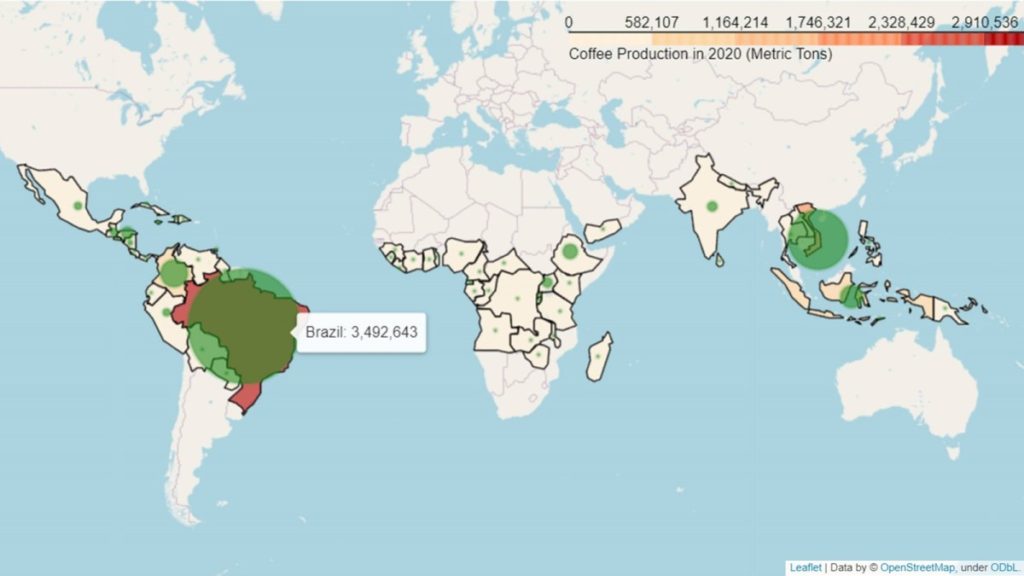
The first four lessons provided me with enough knowledge to use a publicly available dataset on global coffee production to create my own geospatial visualisation with Choropleth and Circle plots. Which I thought was quite a good achievement after just a few hours of online lessons.
But the most powerful takeaway from this module is probably knowing how to conduct proximity analysis to answer questions like:
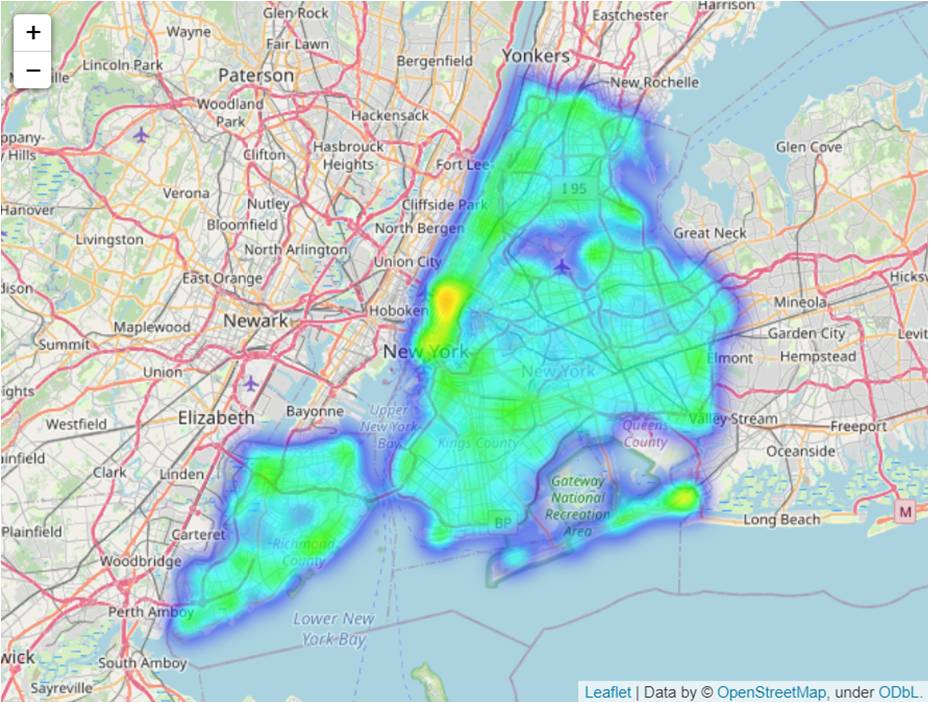
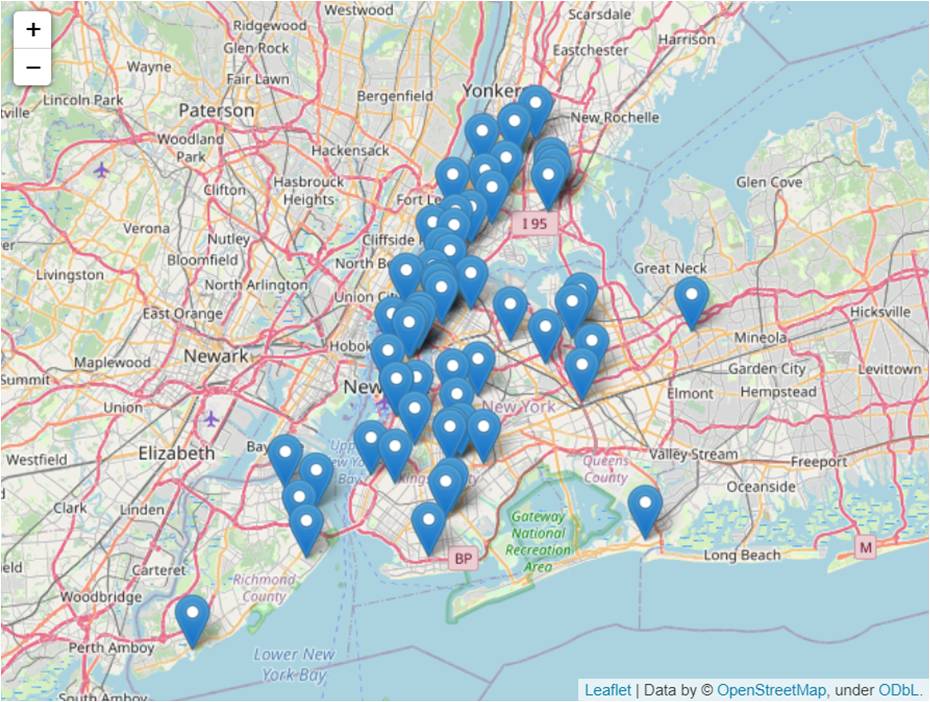
"Given data on motor vehicle collisions and existing hospital locations, where should a city construct new hospitals to minimise coverage gaps?"Which is exactly the scope of the exercises in the final lesson. It uses New York collision data across a five-year period, geographical location of existing hospitals and maps them using open-source data from OpenStreetMap.
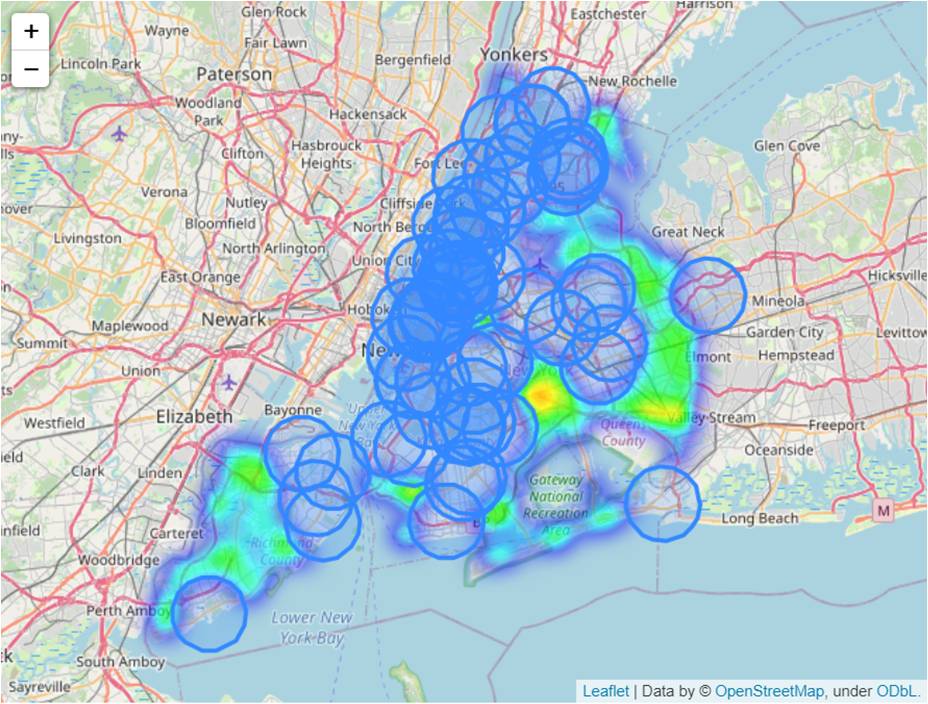
A 10km radius is then drawn around each hospital and a heatmap of collisions that occur outside is overlaid on the same map. The coverage gaps can be clearly seen from the map visualisation, and data-driven decisions on potential new hospital locations can be made.
I can’t think of a specific use case where I’d need to do similar analysis at the moment, but I’m quite certain it will come in handy, sometime in the future. When that happens, I’ll definitely loop back and re-visit the code in the exercises.
Natural Language Processing
As I’m writing this post, I noticed that the NLP module no longer appears in the Kaggle Learn course list. It’s unclear why they chose to remove this particular module, but my best guess is that they probably wanted to refactor the content and possibly increase the number of topics.
Having previously forked the exercise notebooks and saved them in my own account, I was able to trace back the links to the original content. They’re listed below, if you’re interested to take a look:
- Intro to NLP: Tutorial, Exercise
- Text Classification: Tutorial, Exercise
- Word Vectors: Tutorial, Exercise
The course objectives are mentioned in the opening paragraphs of the first tutorial, and the exercises are centred around the usage of the Spacy package.
In this course about Natural Language Processing (NLP), you will use the leading NLP library (spaCy) to take on some of the most important tasks in working with text.
By the end, you will be able to use spaCy for:
– Basic text processing and pattern matching
– Building machine learning models with text
– Representing text with word embeddings that numerically capture the meaning of words and documents
I won’t go deeper into the contents of the module, since it has been removed from the official course list. Hopefully it’ll make a reappearance soon, with a new and improved version.
Intro to Game AI and Reinforcement Learning
The Game AI course was designed around the Connect X beginners simulation competition, and the lessons introduced various heuristics. Starting with a simple one-step lookahead, to the more complex n-step lookahead using a minmax algorithm and finally to deep reinforcement learning.

To be honest, it was all a bit too much for me to absorb. I managed to follow along the tutorials and do the exercises but the tail-end of the course, especially the part on deep reinforcement learning, mostly went over my head.
I did the bare minimum to complete the course and qualify for the completion certificate, but I would definitely have to do the course again, before I can truly say that I understand the content.
Of all the Kaggle Learn courses, this was definitely the most challenging one for me.
Time Series
Thankfully, I found the final module dealing with Time Series easier to digest.
The lessons focus on using machine learning for forecasting, and introduce different techniques to model trends, cycles and seasonality. They also explain how to build hybrid models by using one to model the trend, and then using another model on the residuals to extract patterns.

I found the use of Fourier features (pairs of sine and cosine curves) to model seasonality a particularly interesting approach.
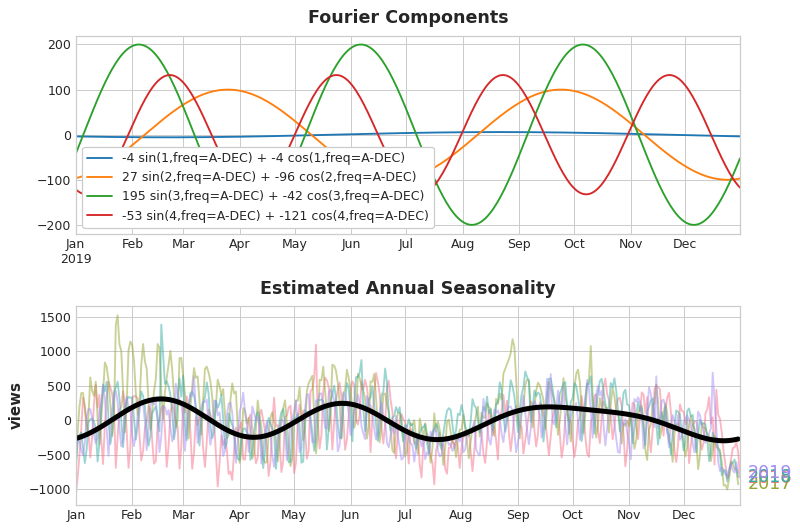
Coding it using CalenderFourier and DeterministicProcess contained in the statsmodels.tsa.deterministic package also seems relatively straightforward, as can be seen in the two code cells below.
Another interesting idea was the use of hybrid models, such as linear regression on the time index to model the trend, followed by XGBoost on the residuals to capture the patterns with the time series.
The general process is described in the pseudocode provided within the tutorial:
# 1. Train and predict with first model
model_1.fit(X_train_1, y_train)
y_pred_1 = model_1.predict(X_train)
# 2. Train and predict with second model on residuals
model_2.fit(X_train_2, y_train - y_pred_1)
y_pred_2 = model_2.predict(X_train_2)
# 3. Add to get overall predictions
y_pred = y_pred_1 + y_pred_2Conclusion
The courses on Kaggle Learn are designed to equip data science and machine learning beginners (like me!) foundational skill sets, as well as introduce the broad range of applications possible. Some courses are simpler and easier to follow, while others are deeper and more challenging.
It took me a while to finally complete all 17 modules, with several starts and stops over the course of several months. But knowing that there was a tangible outcome and a clear end-in-sight helped motivate me to keep taking the next step, and the step after that.
So, if you’re interested in getting a taste of what the world of machine learning has to offer, beginning with the (free!) online courses on Kaggle Learn is a great starting point.
I know that it definitely was for me.
[…] […]