Immediately after completing Kaggle’s “30 Days of ML” challenge, I started on their “Intro to Deep Learning” online course which was estimated to take four hours to complete.
It comprised six sets of tutorials and exercises (plus an additional bonus lesson), starting from the basic building block of a single neuron and ending with a complete implementation of a neural network to predict hotel cancellations using a binary classifier.

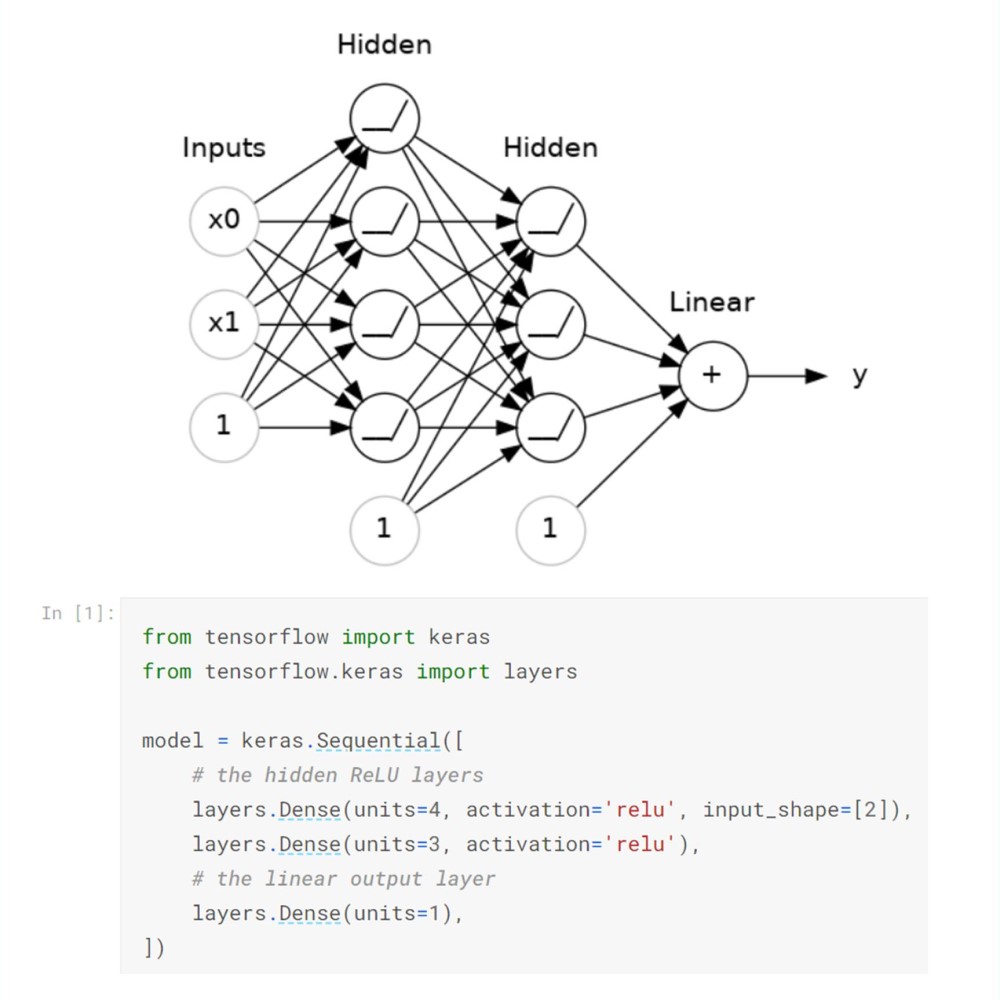
Keras running on top of TensorFlow was the deep learning framework used throughout the course, and configuration was surprisingly easy and straight-forward. For example, in the second tutorial, setting up a sequential neural network with two inputs, two hidden layers and one linear output required only six lines of Python code.
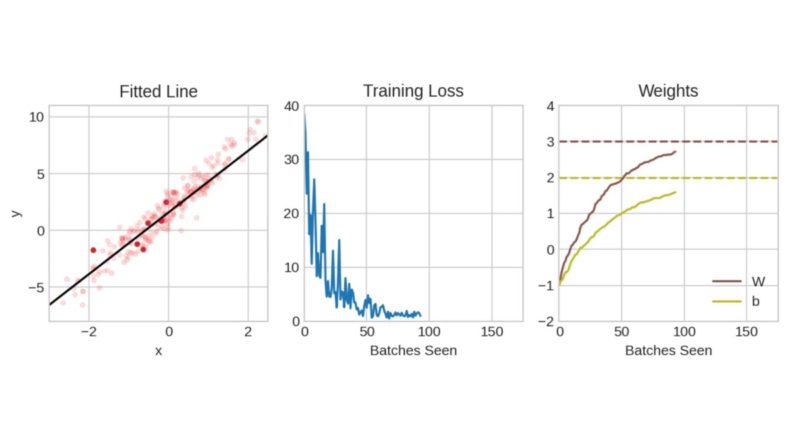
After covering the basics, the important Stochastic Gradient Descent algorithm was introduced and explained using a simple linear model y = 3W + b, where the true values of W and b are 3 and 2 respectively.
Starting with values of -1 for both W and b, the neural network is trained iteratively to minimise a loss function (mean absolute error) by successively changing the values of W and b until the loss function converges to a minimum value.
Each step of the algorithm does the following tasks:
- Randomly (hence “stochastic”) sample a subset of the training data and run it through the neural network to make predictions
- Measure the loss between the predicted and true values
- Adjust the weights in the neural network in a direction that makes the loss smaller (hence “gradient descent”)
Kaggle created an animated gif that clearly and succinctly illustrates the process. In the “Fitted Line” chart, the pale red dots represent the entire set of training data, and the dark red dots represent the subset that was randomly chosen for that particular Batch.

As the number of batches increases, the “Training Loss” reduces and converges to a minimum while the “Weights” converge to their true values. Once all the training data is fully utilised, an Epoch is said to have been completed and the cycle repeats itself.
This simple example only shows what happens during one epoch, but many epochs are usually needed to properly train a neural network.
After setting up a neural network model, compiling and running the model is equally straight-forward, requiring just a few more lines of code.
As the training progresses, Keras conveniently outputs the results for each epoch, including interim results both training and validation losses. These can be subsequently plotted on a graph for easy visualisation of how well the model was trained.



Once you reach this halfway mark in the course, you’re armed with a basic toolbox that will allow you to build, train and run a deep learning model. The course then proceeds to cover additional concepts and features that would improve model performance.
The first enhancement is the addition of Early Stopping and Callbacks to achieve the optimal balance between underfitting and overfitting the model.
In-sample training loss will decrease as the number of epochs increase (blue line), but out-of-sample validation loss (yellow line) may initially decrease but then start increasing at a certain point, indicating that overfitting is starting to occur.


This can be addressed by adding early_stopping and callbacks in the model, so that training is stopped once overfitting is observed. The variables that control when early stopping is triggered are min_delta (minimum amount of change to count as an improvement) and patience (number of epochs to wait before stopping).
Patience is needed because further improvements may take a few epochs to materialise, and setting it to a low (or even zero) value may prematurely stop training. I really like how this variable was named; it’s just so intuitive.
Finally, restore_best_weights=True ensures that the training weights are remembered and the best ones are used for the model, especially when patience is set to a high value.
The second enhancement is the use of Dropout layers to prevent overfitting by learning spurious patterns. The basic idea is that random nodes in a layer are dropped out (see left animation) from the training process, making the neural network work harder to find broad and general patterns. If you’re familiar with Random Forest models, it’s conceptually similar to the Bagging technique.


The third enhancement is the addition of Batch Normalisation layers which rescales the data to a common scale (similar to scikit-learn StandardScaler or MinMaxScaler), making the training more stable. When used as the first layer, it has the added benefit of functioning as an adaptive preprocessor.
Kaggle provides the following explanation: “The reason is that Stochastic Gradient Descent will shift the network weights in proportion to how large an activation the data produces. Features that tend to produce activations of very different sizes can make for unstable training behavior.”

After completing all six tutorials and exercises, I decided to conduct a simple field-test and implement a deep learning model for the “30 Days of ML” competition, using the concepts and techniques that I’d just learnt. I didn’t do much tuning and just wanted to see if I could put together a half-decent working model, outside of the guided tutorials.



Running it on regular CPUs on Kaggle took quite some time, so it was good that they kindly provided 30 hours of free GPU usage each week. Training a deep learning model on GPUs drastically reduces training time.
For example, my code above took 24 minutes to run on Kaggle CPUs but only took 3 minutes on their GPUs, which was 8 times faster!
When I submitted the predictions, it didn’t improve on my best score using XGBoost. I was hoping it would, but I guess deep learning isn’t always a magic bullet.

Overall, taking the online course was definitely time well spent. If you’re new to deep learning and are interested to learn more, I’d say that investing four hours on this Kaggle Learn course is definitely worth the effort.
I am a new user of this site, so here I saw several articles and posts published on this site, I am more interested in some of them, hope you will provide more information on these topics in your next articles.
My blog covers a few topics, and if you’re mainly interested in my data science posts, you can follow my Facebook page https://www.facebook.com/mydatasciencejourney to get updates when I publish DS-related posts.
[…] […]